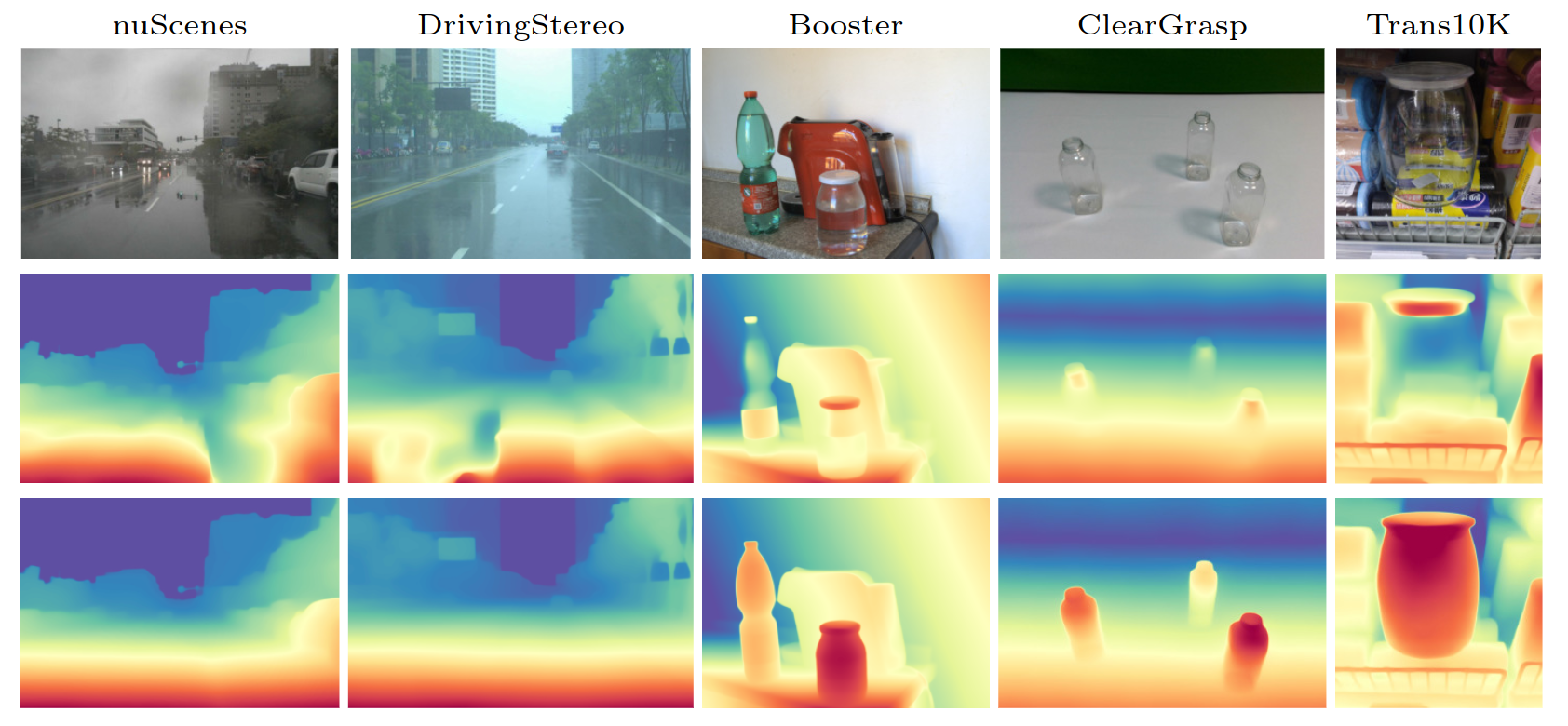
Our method demonstrates the ability to generate diverse driving scenes with challenging weather conditions.
By leveraging diffusion models, we can create a wide range of adverse weather scenarios,
allowing for comprehensive training and evaluation of depth estimation models in diverse environmental conditions.
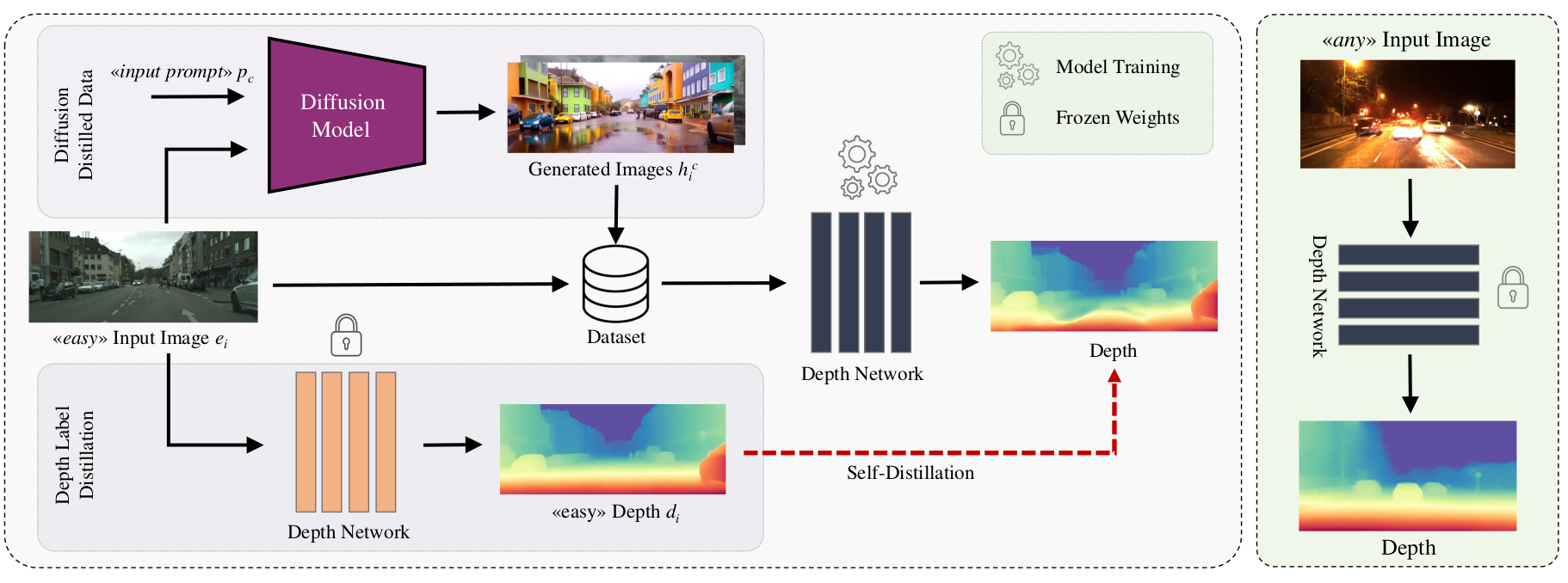
This figure illustrates our process of transforming easy scenes with opaque objects into challenging ones with
transparent and mirrored surfaces. Text-to-image diffusion models with depth-aware control make it possible to preserve the underlying 3D structure while altering the visual appearance, creating complex scenarios for depth estimation that are traditionally difficult to capture or annotate.
Citation
@inproceedings{tosi2024diffusion,
title = {Diffusion Models for Monocular Depth Estimation: {Overcoming} Challenging Conditions},
author = {Tosi, Fabio and {Zama Ramirez}, Pierluigi and Poggi, Matteo},
booktitle = {European Conference on Computer Vision ({ECCV})},
year = {2024}
}